Writing A Simple Brainf**k Interpreter in C#
Introduction
Why did I make this?
Recently, I've been relatively bored on what to work on, despite personal projects - I've gotten a little bit worn out on them and wanted something else to do. Whilst mindlessly exploring the internet, I once again came across Brainf**k, a minimalistic esoteric programming language created by Urban Müller in 1993, and just like I did for Little Man Computing (LMC) - I decided to create an interpreter for it.
PS. You can even view the source here!
How did I make it?
In order to make this project, I outlined the initial requirements of the project, which was to have a portable .NET Brainf**k interpreter, runnable on anything which supports the .NET Framework 4.8. This meant that it would support all operating systems without any hassle.
It follows the same principle as my Little Man Computing interpreter, being split into two components:
- Parser
- Interpreter
Components
Parser
The concept of the parser for this is very simple:
- Go through the file, character by character
- Identify what instruction the character represents
- Storing the new tokenised (instruction) representation of the character
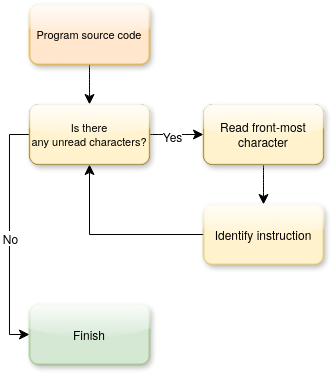
This is importantly because of how simple the language is. There is no need to concern about anything even over two characters - it's mostly just mapping the characters to their relative bytecode.
Each instruction identified is referenced to as a token as per standard. The only other characteristic other than the bytecode/type identifier is the pre-calculated jump for branch instructions.
Features
Pre-processing
But, as much as this is usable - it does not support comments, newlines, white spaces, etc. - all useful in organising code to be readable by humans.
Many Brainf**k programs enjoy these features too, hence why I added pre-processing for this. In the options of the parser, each feature can be toggled but enables programs to be more neatly kept, therefore adding support for:
- **Split Lines
- Comments
- White spaces
- Stripping of Invalid Characters, intended to serve as an alternative to comments
private string PrepareContent(string content) {
// Strip invalid
if (options.StripInvalid) {
content = new string(content.Where(c => options.Syntax.IncrementPointer == c ||
options.Syntax.DecrementPointer == c ||
options.Syntax.IncrementByte == c ||
options.Syntax.DecrementByte == c ||
options.Syntax.OutputByte == c ||
options.Syntax.InputByte == c ||
options.Syntax.LoopStart == c ||
options.Syntax.LoopEnd == c).ToArray());
return content; // No need to continue if we are stripping invalid characters
}
// Strip newlines
if (options.StripNewlines) {
content = content.Replace("\n", "").Replace("\r", "");
}
// Strip whitespaces
if (options.StripWhitespaces) {
content = content.Replace(" ", "");
}
// Handle comments
if (options.Comments.Enabled) {
int openIndex = content.IndexOf(options.Comments.OpenComment);
while (openIndex != -1) {
int closeIndex = content.IndexOf(options.Comments.CloseComment, openIndex + options.Comments.OpenComment.Length);
if (closeIndex == -1) break; // No closing comment found
content = content.Remove(openIndex, closeIndex - openIndex + options.Comments.CloseComment.Length);
openIndex = content.IndexOf(options.Comments.OpenComment, openIndex);
}
}
return content;
}Early Syntax Validation
In addition to this, I added early syntax validation. Even though it is partially redundant due to how the operator functions, it catches errors early on and is considerate of loops - ensuring that the number of loop start/end tokens are equal.
This operates after the source has been processed as otherwise comments and many other things would get flagged by it.
private void ValidateSyntax(string content, ParserOptions.SyntaxOptions syntaxOptions) { // TODO: Loop scope validation
Stack < int > loopStack = new();
foreach(char c in content) {
if (c != syntaxOptions.IncrementPointer &&
c != syntaxOptions.DecrementPointer &&
c != syntaxOptions.IncrementByte &&
c != syntaxOptions.DecrementByte &&
c != syntaxOptions.OutputByte &&
c != syntaxOptions.InputByte &&
c != syntaxOptions.LoopStart &&
c != syntaxOptions.LoopEnd) {
throw new ArgumentException($"Invalid character '{c}' found in the content.");
} else if (c == syntaxOptions.LoopStart || c == syntaxOptions.LoopEnd) {
if (loopStack.Count > 0 && loopStack.Peek() != c) {
loopStack.Pop();
} else {
loopStack.Push(c);
}
}
}
if (loopStack.Count > 0) {
throw new ArgumentException("Unmatched loop start or end detected.");
}
}Interpreter
But with the parser done, there was very little trouble left in interpreting Brainf**k as it is only composed of a set of actions and no more. It was only just interpreting it - oddly enough the simplest aspect of it as there is only a short and simple set of possible instructions.
The way I went about going it was by having a step method which is repeatedly called until the instruction pointer was out-of-range, indicating that the program had finished.
public void Run() {
while (!IsComplete()) {
Step();
}
}
public void Step() {
Token token = tokens[instructionPointer];
instructionPointer++;
int dp = dataPointer; // Cached for faster local access
switch (token.Bytecode) {
case TokenBytecode.INCREMENT_POINTER:
dp++;
if (options.Wraparound && dp >= data.Length) {
dp = 0;
}
break;
case TokenBytecode.DECREMENT_POINTER:
dp--;
if (options.Wraparound && dp < 0) {
dp = data.Length - 1;
}
break;
case TokenBytecode.INCREMENT_BYTE:
data[dp]++;
break;
case TokenBytecode.DECREMENT_BYTE:
data[dp]--;
break;
case TokenBytecode.OUTPUT:
ProvideOutput(data[dp]);
break;
case TokenBytecode.INPUT:
data[dp] = RequestInput();
break;
case TokenBytecode.BRANCH_ZERO:
if (data[dp] == 0) {
instructionePointer = token.Jump;
}
break;
case TokenBytecode.BRANCH_NON_ZERO:
if (data[dp] != 0) {
instructionPointer = token.Jump;
}
break;
default:
throw new InvalidOperationException($"Unknown token bytecode: {token.Bytecode}");
}
dataPointer = dp;
}
public bool IsComplete() {
return instructionPointer >= tokens.Length || instructionPointer < 0;
}I/O Events
The only requirement for the interpreter is the I/O events, which are handled using C#'s built-in event functionality. The triggers are defined as delegates (a type safely encapsulating a method):
public delegate byte InputTrigger();
public delegate void OutputTrigger(byte data);which are then defined as optional events:
public event InputTrigger? OnInput;
public event OutputTrigger? OnOutput;and wrapped in methods:
/* Handle input/output */
private byte RequestInput() {
if (OnInput != null) {
foreach(InputTrigger trigger in OnInput.GetInvocationList()) {
return trigger.Invoke();
}
}
return 0;
}
private void ProvideOutput(byte data) {
if (OnOutput == null) {
return;
}
foreach(OutputTrigger trigger in OnOutput.GetInvocationList()) {
trigger.Invoke(data);
}
}simplifying usage as you may attach multiple events although would not correctly function for providing an input.
Conclusion
I ended up being quite happy with the end product. The performance was decent but does not compare well to ones such as fabianishere's which is written in C.
- ← Previous
Hosting my School Notes for Free